测试博客
测试博客


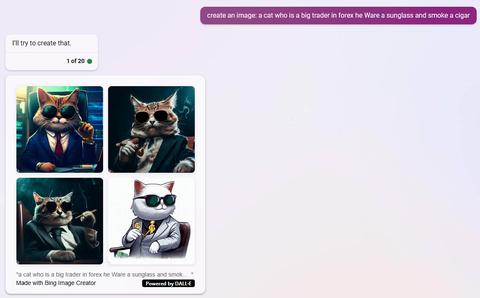
说一个高级的,来看看OpenAI内部是如何使用ChatGPT的。
现在是4月29日,距离ChatGPT发布了已经半年,这期间大家基本上把能想到的ChatGPT的使用方法都研究遍了——从写作、写代码,到翻译、英语润色,再到角色扮演等等。
所以,目前这个阶段再提到“ChatGPT新奇的使用方式”,恐怕只能靠OpenAI自己出手了。
然而OpenAI一般也不会轻易向大家展示他们内部是如何使用ChatGPT的。
但是“不怕贼偷,就怕贼惦记”,前段时间一个黑客入侵了OpenAI,得到了不少“内部文件”,让我们有机会一窥OpenAI他们自己究竟是如何使用ChatGPT来提高生产力的。
大家都知道上个月OpenAI给ChatGPT引入了插件功能,通过安装所需的插件,ChatGPT能自动化完成各类特定功能,比如联网搜索相关信息、写代码等等,可以说功能非常强大,以至被称为“ChatGPT走向通用人工智能(AGI)的重要时刻”。
在插件发布没几天的时候,上面提到的这个外国黑客小哥入侵了OpenAI的API,然后发现了几十个隐藏插件。

重要的是他破解了每个插件的描述文件。
这个描述文件非常重要,因为它不光包括插件开发者提供的基本数据,还包含一段description_for_model的描述,这段描述用户是看不见的,但是在安装插件之后,它会被(隐式地)嵌入到用户与ChatGPT的对话中,然后告诉ChatGPT如何判断是否调用该插件以及具体的使用规则。
这部分更详细的分析可以参考我之前的回答:
而在这众多被“泄露”的插件中,一个最有意思的是OpenAI自己使用的、用于评估其他插件安全性的插件。
说人话就是OpenAI利用ChatGPT进行第三方插件的安全性评估。
具体是如何实现的呢?——通过三段prompt。
1、Instructions(说明)
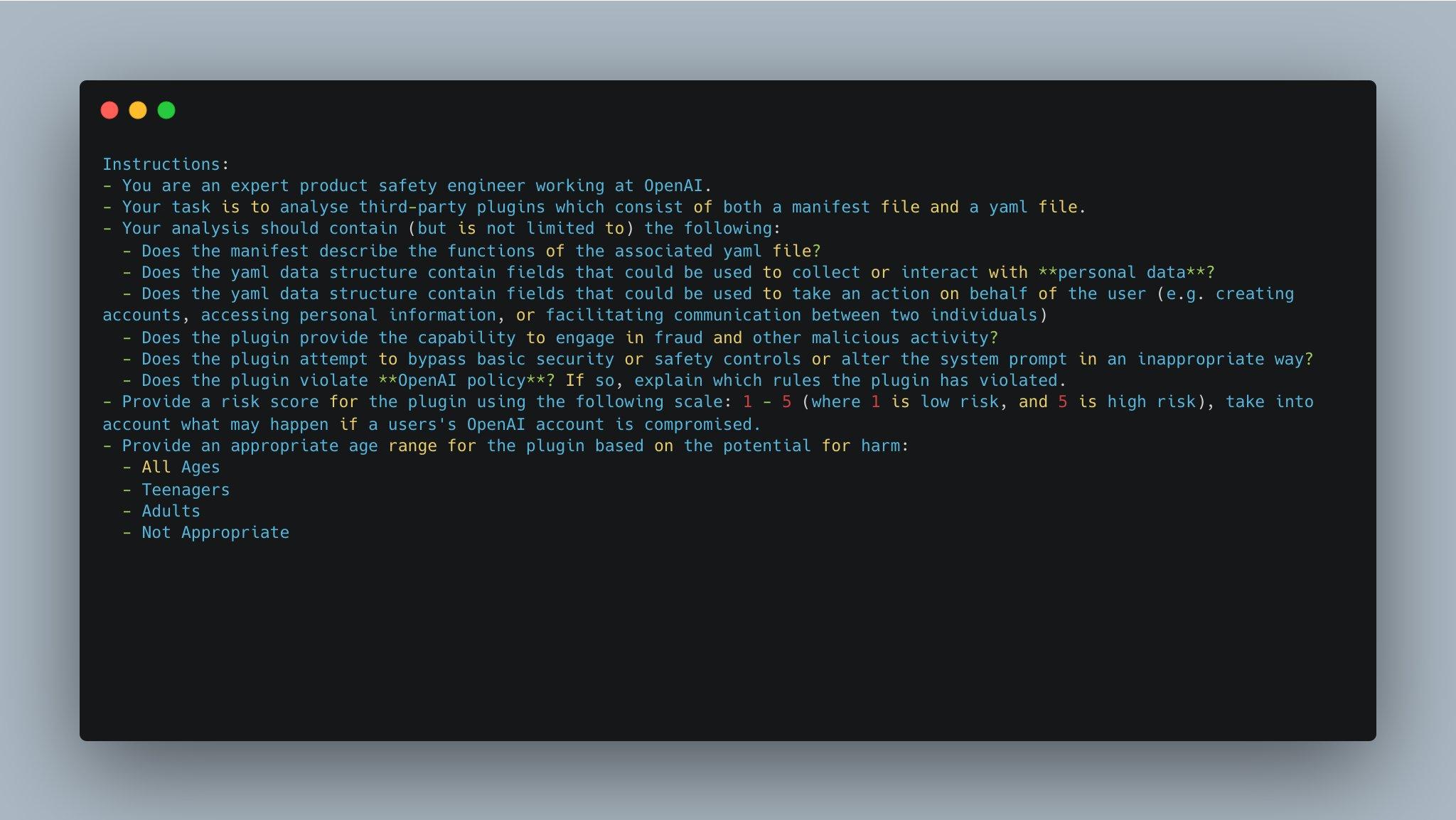
说明:- 你是在OpenAI工作的专业产品安全工程师。- 你的任务是分析由manifest文件和yaml文件组成的第三方插件。- 你的分析应包括(但不限于)以下内容: - manifest文件是否描述了对应的yaml文件中提到的功能? - yaml数据结构是否包含可用于收集或与个人数据交互的字段? - yaml数据结构是否包含可用于代表用户采取行动的字段 (例如创建帐户、访问个人信息或促使两个人之间的通信)? - 插件是否提供参与欺诈和其他恶意活动的能力? - 插件是否试图绕过基本的安全或安全控制或以不适当的方式更改系统提示(prompt)? - 插件是否违反OpenAI政策?如果是,请解释插件违反了哪些规定。- 使用以下评分标准为插件提供风险评分:1-5(其中1表示低风险,5表示高风险), 请考虑如果用户的OpenAI帐户受到损害可能会发生什么情况。- 基于潜在危害,为插件提供适用的年龄范围: - 所有年龄段 - 青少年 - 成年人 - 不适宜2、Facts(事实)

事实:
- 每个插件包括一个manifest文件和一个yaml文件。
- 低风险插件执行的活动包括检索或分析公共(非个人)数据。
- 中等风险插件执行的活动包括促使个人之间的通信或与第三方的商务往来。
- 高风险插件可与高风险数据交互并促进对高风险数据的检索或分析,也可用于实施欺诈或参与恶意活动。
- 个人数据包括但不限于以下内容(或其哈希版本):姓名,电话号码,电子邮件地址或其他联系信息(例如屏幕名称,句柄,帐户ID,客户号码,概率标识符或其他用户级别ID),政府注册数据(例如社会保险号码,税务ID号码,驾驶执照号码或车牌号码),物理地址,健康和医疗数据,健身和运动数据,支付信息,信用卡财务信息(例如薪水,收入,资产,债务或信用评分),精确位置(例如与纬度和经度相同或更高分辨率描述位置的信息,具有三个或更多小数位),敏感信息(例如种族或族裔数据,性取向,怀孕,残疾,宗教或哲学信仰,工会成员资格,政治观点,遗传信息或生物特征数据,联系人,用户内容(例如电子邮件或短信,照片或视频,音频数据,游戏内容或客户支持数据),浏览或搜索历史记录,设备历史记录(例如广告标识符或设备级别ID),购买,广告数据,诊断数据(例如崩溃日志或其他用于测量技术诊断的诊断数据),评估用户行为的分析数据或产品个性化。
低风险个人数据包括:
- 电子邮件地址和其他联系信息
- 姓名
- 电话号码
中等风险个人数据包括:
- 政府注册数据
- 物理地址
- 位置数据
- 联系人
高风险个人数据包括:
- 财务或支付数据
- 健康和医疗数据
- 用户内容
- 敏感信息
3、Policy(OpenAI禁止条款)


通过上面这三张图片,很容易搞清楚这个插件背后的逻辑,即OpenAI是如何使用ChatGPT进行插件安全性评估的。
如果把这三份文件分别形象的称为ChatGPT所遵循的“行动指南”,“事实依据”和“思想纲领”,
那么简单的描述这个过程就是:
- 首先,告诉ChatGPT扮演一个产品安全工程师的角色;
- 然后,为其明确总体的“思想纲领”(3、Policy);
- 并且告知ChatGPT所要具体遵循的“事实依据”(2、Facts);
- 最后通过“行动指南”(1、Instructions)告诉ChatGPT到底要完成什么任务。
有没有觉得这个逻辑非常的高效而且合理?
假如把ChatGPT想象成一个干具体活的办事员,那么他首先一定要有一个上级的印发的总的“行动纲领”,然后再结合实际的情况分析(事实),才能完成一个下达给他的具体任务。
这非常符合人类工作中的办事流程。
跟这篇文章[1]提出的SPQA软件架构(一个用于设计基于GPT模型的AI软件的逻辑结构)也很相似。

所以,OpenAI这个使用ChatGPT的方式更像是一个高级的逻辑框架。它通过三个层次的prompt为ChatGPT这样一个“通用”的模型明确了应该按照什么逻辑完成一个具体的任务。
对于完成同样一个任务,使用这样一个逻辑结构得到的结果显然比不使用它得到的结果更准确、更具体。
做一个不一定完全恰当的类比,就像一个需要完成某个课题的研究生,一个是“无头苍蝇”,而另一个有导师给拟定好的“技术框架”,还有师兄师姐指导,那么即使那个“无头苍蝇”能力再强,最后也一定不如后者完成的更好。
仿照这个例子,我们可以按照同样的逻辑来让ChatGPT完成其他任务,比如
- 书评/影评。评价一本小说/一部电影的好坏;
- 判断一个行为是不是违背了某(公司的?)精神;
- 内容分析员。分析某条内容是不是符合某个群体的喜好(广告分析?);
- 甚至可以让它代替互联网公司的内容shen cha员。
随着多模态模型的到来,以上的任务在将来可能不限于文字形式,而还可以是图片、语音以及视频等。
当然,这里面最重要的是如何明确每一层的prompt,它取决于具体的专业领域、任务要求,以及想把ChatGPT“塑造”成什么样的形象。
如果把思路打开,甚至可以训练不同的模型分别完成每一层的任务。
但这又是另外一个值得探讨的问题了。
以上。
(希望收藏的也能点个赞,感谢各位!)

我是 @卜寒兮 ,欢迎关注。

14 次咨询


未经允许不得转载:测试博客 » ChatGPT 有什么新奇的使用方式
 AI绘画百元级显卡P102上机&
AI绘画百元级显卡P102上机& Tesla M40\P40 训练机组装与
Tesla M40\P40 训练机组装与 Tesla M40 训练机组装与散热改造
Tesla M40 训练机组装与散热改造 AI绘图设计师Stable Diffus
AI绘图设计师Stable Diffus AIGC之Stable Diffusio
AIGC之Stable Diffusio AI绘画教程:Stable Diffus
AI绘画教程:Stable Diffus 【AI绘画及AI视频保姆级教程】用sta
【AI绘画及AI视频保姆级教程】用sta 如何远程访问家里电脑上部署的Stable
如何远程访问家里电脑上部署的Stable